Preparación de datos

Hasta ahora, hemos visto como el análisis de los dataset nos muestra a
simple vista patrones específicos que nos permiten realizar conclusiones
sobre lo que se estudia. Pero, ¿Qué pasa si nos faltan datos? ¿Qué
ocurre si hay datos que serían imposibles dado el dominio del
problema?.
En esta sección, definiremos los tipos de problemas más importantes que
puede traer un dataset y veremos un ejemplo en Rapidminer de cómo
solucionarlos.
Datos faltantes

Uno de los problemas más ocurrentes en el estudio de los dataset, es encontrarse con datos faltantes. Específicamente, cuando nos faltan columnas en un dato en lugar del dato entero. Imaginémonos el ejemplo del dataset Iris visto en la sección anterior. ¿Qué ocurriría si de una flor tuviera el largo de los pétalos y sépalos pero me faltaran los anchos? ¿Cómo manejo el problema?
Existen varias soluciones para el problema de los datos faltantes:
-
Eliminarlos: Si veo una fila en un archivo con datos faltantes como en el ejemplo anterior, entonces elimino la fila entera. Este enfoque permite solucionar el problema rápidamente pero a costa de la pérdida de datos de entrenamiento. Es una alternativa que se utiliza únicamente cuando se tienen datasets grandes y muy pocas filas con datos faltantes (o si la fila tiene tantos datos faltantes que no vale la pena utilizarla).
-
Intuir el dato: La otra alternativa a eliminar el dato entero, es tratar de generar la columna faltante utilizando el resto de los datos. Existen varios métodos para este propósito, desde utilizar el promedio del resto de los datos en caso de que el faltante sea numérico (Por ejemplo, si nos falta el ancho del pétalo como en el ejemplo anterior, ponerle de valor el promedio del resto de los anchos) hasta analizar el conjunto de datos entero en búsqueda de patrones para ver que valor ponerle al dato faltante en base al resto de sus atributos.
Datos fuera de rango (Outliers)
Los outliers son otro problema que puede ocasionar efectos áltamente
negativos en el rendimiento de nuestros modelos. Un outlier es todo
aquel dato que tiene valores que a primera vista son imposibles en el
contexto estudiado. Por ejemplo, si tuvieramos un dataset de personas y
una de ellas tuviera una altura de 5 metros, sin lugar a dudas sabemos
que eso es imposible.
Como la computadora no sabe razonar que un dato es imposible, lo toma
por válido y ajusta el modelo para cubrir esos casos, lo cual impacta
negativamente en su evaluación de nuevos datos.
Los métodos para resolver este tipo de increpancia, son práticamente los mismos que los vistos para los datos faltantes, solo que en este caso, suele ser mejor su eliminación a su modificación, ya que a veces ocurre que todas las columnas del dato están comprometidas o es más complicado de lo que parece arreglarlas y podría tener efectos muy negativos en la data. Obviamente hay casos en los cuales no podemos prescindir de esos datos y debemos modificarlos. Un ejemplo claro sería la recopilación de datos del movimiento de una persona caminando, donde tomamos el valor de la altura de un pie cada medio segundo. Si vemos que desde medio segundo a otro, el pie aumentó 2 metros en altura podemos estar seguros de que es un outlier, pero sabiendo el dato previo y posterior, podríamos cambiarlo para que represente el promedio de ellos (Por ejemplo, si la altura 0.5 segundos antes fuera 0.34m y la altura 0.5 después fuera 0.36, podríamos con cierta certeza estimar el valor fuera rango como 0.35m).
Una última consideración con los outliers es que, a diferencia de los datos faltantes, estos podrían no ser outliers siquiera. El problema con los outliers, es que los reconocemos por estar muy por fuera de la tendencia de los datos en el dataset, pero los hechos extraordinarios pueden ocurrir. Un ejemplo muy simple sería si tuvieramos los datos de las edades de las personas en una localidad y tenemos unos 1000 habitantes entre las edades de 0 y 90 años y luego tenemos una con 112 años de edad. Esta persona perfectamente podría ser real pero a simple vista y dado el contexto, podríamos confundirlo por un dato falso.
Ejemplo en Rapidminer
La mayoría de las herramientas de analisis de datos, ya poseen operadores que manejan datos faltantes y outliers. Para demostrarlo, utilizaremos el ejemplo del tutorial de Rapidminer para preparación de datos.
El tutorial, utiliza un dataset que contiene datos de los pasajeros del titanic y tiene un atributo que determina si la persona sobrevivió o no. El objetivo del mismo es utilizarlo para saber si una persona X sería capaz de sobrevivir al titanic dadas ciertas circunstancias (en la unidad siguiente, se va a realizar une estudio completo de este problema).
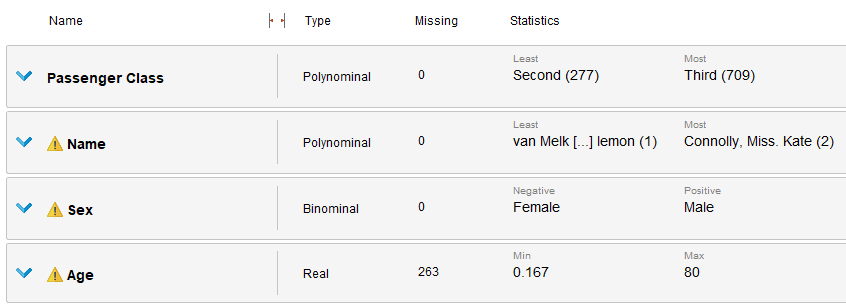
Un analisis inicial en rapidminer, nos revela la cantidad de datos faltantes en cada uno de los atributos del dataset. En este caso, vemos como para la columna de edad, hay 263 datos faltantes de 1309. Al ser un gran porcentaje de los datos, de no realizar ninguna acción, esto podría impactar de forma negativa el rendimiento de un posible modelo. Rapidminer, ofrece un bloque especial para estos casos que se llama "Replace missing values" que hace lo que su nombre indica, reemplaza los datos faltantes con una técnica definida por el usuario. Entre estas técnicas, está el uso del promedio, el máximo o mínimo de los valores encontrados para esa columna, ponerle un 0 o simplemente, llenarlos con un valor arbitrario.

En conjunto, se utiliza el operador "Filter examples" para eliminar por completo las filas con datos faltantes en el resto de los atributos, dado que estos son muy pocos y no afectarán en gran medida al dataset (El operador "Select attributes", fue utilizado para seleccionar la columna "Age").
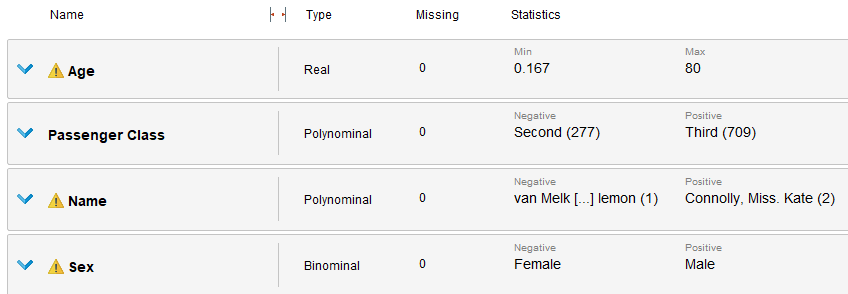
Finalmente, tenemos un dataset limpio, sin valores faltantes. Para manejar outliers y normalizar la data, Rapidminer cuenta con dos bloques, "Detect Outliers" que utilizando un método configurable, marca los datos que considera fuera de rango y nos permite luego eliminarlos. Este operador es usualmente utilizado en conjunción a uno de normalización. La normalización, es un proceso de estandarización de datos a un rango específico que permite que estos se lean de la misma forma para cualquier dato en el conjunto, es muy util y casi que imprescindible utilizarlo al preparar datos.

Es recomendable siempre usar estos 3 operadores en conjunto previo a analizar un dataset para maximizar la eficiencia del analisis y entrenamiento de modelos.
Resumen
Se vió las definiciones para datos faltantes, outliers y la aplicación de normalización en los conjuntos de datos para prepararlos previo a estudiarlos y mejorar nuestros análisis.